Peter Norvig / 青木靖 訳
このエッセイでは、 あらゆる数独パズルを解くという問題に取り組む。制約伝播と探索という2つのアイデアを使うと、ごく簡単に解けるということがわかる(主要なアイデアはコードにして1ページたらずで、補足的なコードが2ページある)。それぞれのユニットのマスが1から9の数字の順列によって埋められるようにする。つまり、1つのユニットに同じ数字が2度現れてはならず、それぞれの数字は必ず1度現れなければならないということだ。それぞれのマスはどのピアとも異なる値を持つことになる。以下にそれぞれのマスの名称、典型的な数独パズル、その解答を示す。
A1 A2 A3| A4 A5 A6| A7 A8 A9 4 . . |. . . |8 . 5 4 1 7 |3 6 9 |8 2 5 B1 B2 B3| B4 B5 B6| B7 B8 B9 . 3 . |. . . |. . . 6 3 2 |1 5 8 |9 4 7 C1 C2 C3| C4 C5 C6| C7 C8 C9 . . . |7 . . |. . . 9 5 8 |7 2 4 |3 1 6 ---------+---------+--------- ------+------+------ ------+------+------ D1 D2 D3| D4 D5 D6| D7 D8 D9 . 2 . |. . . |. 6 . 8 2 5 |4 3 7 |1 6 9 E1 E2 E3| E4 E5 E6| E7 E8 E9 . . . |. 8 . |4 . . 7 9 1 |5 8 6 |4 3 2 F1 F2 F3| F4 F5 F6| F7 F8 F9 . . . |. 1 . |. . . 3 4 6 |9 1 2 |7 5 8 ---------+---------+--------- ------+------+------ ------+------+------ G1 G2 G3| G4 G5 G6| G7 G8 G9 . . . |6 . 3 |. 7 . 2 8 9 |6 4 3 |5 7 1 H1 H2 H3| H4 H5 H6| H7 H8 H9 5 . . |2 . . |. . . 5 7 3 |2 9 1 |6 8 4 I1 I2 I3| I4 I5 I6| I7 I8 I9 1 . 4 |. . . |. . . 1 6 4 |8 7 5 |2 9 3
それぞれのマスは正確に3つのユニットに属し、20のピアを持つ。たとえば、マスC2のユニットとピアは以下のようになる。
A2 | | | | A1 A2 A3| |
B2 | | | | B1 B2 B3| |
C2 | | C1 C2 C3| C4 C5 C6| C7 C8 C9 C1 C2 C3| |
---------+---------+--------- ---------+---------+--------- ---------+---------+---------
D2 | | | | | |
E2 | | | | | |
F2 | | | | | |
---------+---------+--------- ---------+---------+--------- ---------+---------+---------
G2 | | | | | |
H2 | | | | | |
I2 | | | | | |
ユニット、ピア、マスの概念は、プログラミング言語Python (2.5以降)で以下のように実装できる。
def cross(A, B):
"Aの要素とBの要素の外積。"
return [a+b for a in A for b in B]
digits = '123456789'
rows = 'ABCDEFGHI'
cols = digits
squares = cross(rows, cols)
unitlist = ([cross(rows, c) for c in cols] +
[cross(r, cols) for r in rows] +
[cross(rs, cs) for rs in ('ABC','DEF','GHI') for cs in ('123','456','789')])
units = dict((s, [u for u in unitlist if s in u])
for s in squares)
peers = dict((s, set(sum(units[s],[]))-set([s]))
for s in squares)
Pythonに馴染みがない人のために言っておくと、dictあるいはdictionaryというのはPythonのハッシュテーブルで、キーを値に対応づけるのに使われ、組(キー,値)の列によって定義する。dict((s, [...]) for s in squares)で、それぞれのマスsをリスト[...]に対応づけるdictionaryが作られる。式[u for u in unitlist if s in u] は、マスsを要素とするユニットuのリストを意味する。だからこの代入文の意味は、「unitsを、それぞれのマスsを、sを含むユニットのリストに対応づけるdictionaryとする」ということだ。同様に次の代入文は、「peersは、それぞれのマス sを、sのユニットに属するマスの和集合からs自身を除いたものに対応付けるdictionaryとする」という意味だ。
少しばかりテストを書いておいても害はないだろう(すべて通る)。
def test():
"ユニットテスト"
assert len(squares) == 81
assert len(unitlist) == 27
assert all(len(units[s]) == 3 for s in squares)
assert all(len(peers[s]) == 20 for s in squares)
assert units['C2'] == [['A2', 'B2', 'C2', 'D2', 'E2', 'F2', 'G2', 'H2', 'I2'],
['C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9'],
['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']]
assert peers['C2'] == set(['A2', 'B2', 'D2', 'E2', 'F2', 'G2', 'H2', 'I2',
'C1', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9',
'A1', 'A3', 'B1', 'B3'])
print 'All tests pass.'
これでマスとユニットとピアができたので、次に数独の盤面(grid)を定義しよう。実際には二通りの表現が必要になる。ひとつは、パズルの初期状態を与えるためのテキスト形式だ。このためにgridという名前を使うことにする。もうひとつは、部分的に解けたものや、最後まで解けたものを含む、任意の時点におけるパズルの内部状態を表す表現形式だ。これはvaluesコレクションと呼ぶことにしよう。それぞれのマスについて、その取り得る値すべてを保持させるからだ。 テキスト形式の方には 文字列を使い、1-9で数字を、0かピリオドで空いているマスを表し、それ以外の文字は無視するものとする(スペース、改行、横棒、縦棒を含む)。したがって以下の3つのgrid文字列はいずれも同じパズルを表している。
"4.....8.5.3..........7......2.....6.....8.4......1.......6.3.7.5..2.....1.4......" """ 400000805 030000000 000700000 020000060 000080400 000010000 000603070 500200000 104000000""" """ 4 . . |. . . |8 . 5 . 3 . |. . . |. . . . . . |7 . . |. . . ------+------+------ . 2 . |. . . |. 6 . . . . |. 8 . |4 . . . . . |. 1 . |. . . ------+------+------ . . . |6 . 3 |. 7 . 5 . . |2 . . |. . . 1 . 4 |. . . |. . . """
次にvaluesについてだが、9 x 9の配列が当然のデータ構造だろうと思うかもしれない。しかしマスには (0,0)ではなく'A1'のような名前がついているので、valuesはマスをキーとするdictがよいだろう。それぞれのキーに対する値には、そのマスに入りうる数字を保持する。パズルの定義で数字が割り当てられているマスや、何が入るはずか既にわかっているマスであれば1個の数字になり、まだ未確定なマスであればいくつかの数字のコレクションになる。この数字のコレクションはPythonのsetかlistで表現できるが、ここでは数字からなる文字列を使うことにした(その理由は後で説明する)。したがってA1が7でC7が空の盤面は、{'A1': '7', 'C7':'123456789', ...}. のように表される。
以下は盤面のテキスト形式gridを辞書valuesへとパースするコードだ。
def parse_grid(grid):
"""テキスト形式gridを可能な値の辞書{square: digits}に変換する。ただし
矛盾が見つかった場合にはFalseを返す。"""
## 最初それぞれのマスは何の数字でもありうる。それからgridより値を割り当てる。
values = dict((s, digits) for s in squares)
for s,d in grid_values(grid).items():
if d in digits and not assign(values, s, d):
return False ## (マスsにdを割り当てられなければ失敗)
return values
def grid_values(grid):
"テキスト形式gridを辞書{square: char}に変換する。空のマスは'0'か'.'とする。"
chars = [c for c in grid if c in digits or c in '0.']
assert len(chars) == 81
return dict(zip(squares, chars))
(1) あるマスの取り得る値が1つだけなら、その値をピアから取り除く。戦略(1)の例としては、A1に7を割り当てて{'A1':'7', 'A2':'123456789', ...}となったとき、A1には1つの値しかないので、A2(およびその他のピア)から7を取り除くことができ、{'A1': '7', 'A2': '12345689', ...}となる。戦略(2)の例としては、A3からA9のいずれも値3を取り得ないなら、3はA2に入るはずであり、{'A1': '7', 'A2':'3', ...}へと更新することができる。 A2に対するこれらの変更によって、さらにそのピアや、ピアのピアへと変更が波及しうる。このプロセスは「制約伝播」と呼ばれている。
(2) ある値に対し、ユニットの中で置ける場所が1つしかないなら、その値をそこに置く。
関数assign(values, s, d)は、制約伝播によるものも含め更新されたvaluesを返すが、矛盾がある場合(その割り当てを一貫性を維持しつつ行うことができないとき)、Falseを返す。たとえばgridが'77...'で始まっていたとすると、7はA1に割り当てられた時点でA2から取り除かれるので、assignは7がA2の取り得る値でないと検出することになる。
実は鍵となる操作は値の割り当てよりむしろ、マスから取り得る値を除いていくことであるのがわかる。これは関数eliminate(values, s, d)で実装している。 eliminateを使うと、assign(values, s, d)は「マスsからd以外の値を取り除く」こととして定義できる。
def assign(values, s, d):
""" values[s]からd以外のすべての値を取り除き、伝播する。
valuesを返す。ただし矛盾が見つかった場合はFalseを返す。"""
other_values = values[s].replace(d, '')
if all(eliminate(values, s, d2) for d2 in other_values):
return values
else:
return False
def eliminate(values, s, d):
""" values[s]からdを取り除く。値か場所が1つになったら伝播する。
valuesを返す。ただし、矛盾が見つかったときにはFalseを返す。"""
if d not in values[s]:
return values ## すでに取り除かれている
values[s] = values[s].replace(d,'')
## (1) マスs が1つの値d2まで絞られたなら、ピアからd2を取り除く。
if len(values[s]) == 0:
return False ## 矛盾 最後の値が取り除かれた
elif len(values[s]) == 1:
d2 = values[s]
if not all(eliminate(values, s2, d2) for s2 in peers[s]):
return False
## (2) ユニットuで値dを置きうる場所が1カ所だけになったなら、dをその場所に入れる。
for u in units[s]:
dplaces = [s for s in u if d in values[s]]
if len(dplaces) == 0:
return False ## 矛盾 値を置ける場所がない
elif len(dplaces) == 1:
# ユニットの中でdを置けるところが1カ所しかないので、そこに置く
if not assign(values, dplaces[0], d):
return False
return values
あまり先へ進みすぎる前に、パズルを表示できるようにしておいた方が良いだろう。
def display(values):
"valuesを2次元のテキスト形式で表示する。"
width = 1+max(len(values[s]) for s in squares)
line = '+'.join(['-'*(width*3)]*3)
for r in rows:
print ''.join(values[r+c].center(width)+('|' if c in '36' else '')
for c in cols)
if r in 'CF': print line
print
これで準備ができた。Project Eulerの数独問題から簡単なパズル集の中の最初の例を選んで解いてみた。
>>> grid1 = '003020600900305001001806400008102900700000008006708200002609500800203009005010300' >>> display(parse_grid(grid1)) 4 8 3 |9 2 1 |6 5 7 9 6 7 |3 4 5 |8 2 1 2 5 1 |8 7 6 |4 9 3 ------+------+------ 5 4 8 |1 3 2 |9 7 6 7 2 9 |5 6 4 |1 3 8 1 3 6 |7 9 8 |2 4 5 ------+------+------ 3 7 2 |6 8 9 |5 1 4 8 1 4 |2 5 3 |7 6 9 6 9 5 |4 1 7 |3 8 2
この場合、戦略(1)と(2)を機械的に適用するだけで完全に解くことができる! あいにくと、いつもそううまくいくわけではない。以下は難しいパズル集の最初にある問題だ。
>>> grid2 = '4.....8.5.3..........7......2.....6.....8.4......1.......6.3.7.5..2.....1.4......' >>> display(parse_grid(grid2)) 4 1679 12679 | 139 2369 269 | 8 1239 5 26789 3 1256789 | 14589 24569 245689 | 12679 1249 124679 2689 15689 125689 | 7 234569 245689 | 12369 12349 123469 ------------------------+------------------------+------------------------ 3789 2 15789 | 3459 34579 4579 | 13579 6 13789 3679 15679 15679 | 359 8 25679 | 4 12359 12379 36789 4 56789 | 359 1 25679 | 23579 23589 23789 ------------------------+------------------------+------------------------ 289 89 289 | 6 459 3 | 1259 7 12489 5 6789 3 | 2 479 1 | 69 489 4689 1 6789 4 | 589 579 5789 | 23569 23589 23689
このケースでは、パズルが解けたというのからほど遠い。61個のマスがまだ未確定だ。次はどうすれば良いだろう? もっと洗練された戦略をコーディングすることもできる。たとえば、「裸の双子戦略」では、同じユニットの2つのマスが、可能な値として同じ2つの数字を持つ場所を探す。{'A5': '26', 'A6':'26', ...}となっていたとすれば、2と6はA5とA6に入ることがわかる(どっちがどっちなのかはわからないが)。したがって2と6を、行Aの他のマスから取り除くことができる。関数eliminateにelif len(values[s]) == 2という条件で実行されるコードを数行追加してこの戦略はコーディングできるだろう。
このようにして様々な戦略をコーディングしていくことは可能だが、何百行ものコードを書くことになるだろうし(こういった戦略は何十とある)、それですべてのパズルが解けるのかいつまでたっても確信できないだろう。
別な行き方として解の探索がある。つまり、答えが見つかるまで、すべての可能性を系統的に試していくということだ。これは10行程度のコードで実装できるが、別なリスクもある。実行がいつまでも終わらない可能性があるのだ。上のgrid2の例を考えてみよう。A2には4つの可能性(1679)があり、A3には5つの可能性(12679)がある。組み合わせると20の可能性になる。このように掛け合わせていくと、パズル全体では4.62838344192 × 1038通りの可能性になる。どうやってこれに対処できるのだろう? 2つの選択がある。
第一は、総当たり的なアプローチだ。それぞれの配置を1命令で評価できる非常に効率的なプログラムがあり、次世代テクノロジーを利用できるものとしよう。1024コアの10GHzプロセッサを100万個使うことにして、さらに我々が買い物している間に、タイムマシンを使って130億年前の宇宙の起源まで遡ってプログラムを開始しておくことにしよう。そうするとこのパズルは、今ではほぼ1%解けているという計算になる 。
第二の選択は、どうにかしてマシン命令ごとに1つより多くの可能性を処理するということだ。そんなこと不可能に見えるが、幸いなことに制約伝播がやってくれるのがまさにそれだ。4 × 1038通りの可能性すべてを試す必要はなく、1つ試すと他の多くの可能性を消すことができる。たとえば上の例でH7のマスには6と9という2つの取り得る値があるが、9を試すとすぐに矛盾が生じることがわかる。それによって可能性は1つ取り除かれるだけでなく、4 × 1038通りの選択のうちの半分が消えることになる。
実際、このパズルを解くには、たった25の可能性を調べればよいことがわかる。明示的に探索しなければならないのは61の未確定のマスのうちの9つだけで、残りは制約伝播が片付けてくれる。難しいパズル集にある95問で1つのパズルあたりに検討する必要のある可能性は平均64個で、16マスより多く探索する必要のあるケースはない。
探索アルゴリズムとはどんなものなのか? 単純だ。最初に解が既に見つかるか矛盾にぶつかるかしていないか確認する。そうでない場合に、未確定のマスを1つ選び、取り得る値すべてを検討する。1度に1つずつマスに割り当ててみて、残りの部分を探索する。言い換えると、マスsにdを割り当てた結果からうまく解答が見つかるような値dを探すということだ。探索が失敗に行き当たったなら、戻って別なdの値を検討する。これは再帰的探索であり、深さ優先探索と呼ばれている。マスsに対して他の値を検討する前に、values[s] = dの場合をすべて検討するからだ。
管理が複雑になるのを避けるため、探索関数searchを再帰呼び出しするごとにvaluesのコピーを作ることにする。そうすることで、探索木のそれぞれの枝は独立になり、別な枝と混同するようなことはなくなる。(マスの取り得る値の集合を実装するのに文字列を使うことにしたのはこのためだ。このコピーはvalues.copy()で行えて効率的だ。もしPythonのsetやlistを使って実装していたら、copy.deepcopy(values)を使う必要があり、これはあまり効率的ではない。) 別なやり方として、valuesに対するそれぞれの変更を管理し、行き止まりになったら変更を元に戻すという手もある。このやり方はバックトラッキングとして知られている。探索のそれぞれのステップが大きなデータ構造に対する1カ所の変更であるような場合には意味のあるやり方だが、それぞれの割り当てが制約伝播で他のたくさんの変更を引き起こす場合には話が複雑になる。
この探索を実装する上で2つの選択がある。変数の順序(どのマスを最初に試すか?)と、値の順序(そのマスに対してどの数字を最初に試すか?)だ。変数の順序には、MRV(Minimum Remaining Values)と呼ばれる一般的なヒューリスティックスを使う。取り得る値が一番少ないマス(の1つ)を選ぶということだ。なぜそうするのか? 上のgrid2の例を考えてみよう。B3を最初に選んだなら、可能性は7つ(1256789)あり、確率6/7で間違った選択をすることになる。代わりにG2を選んだなら、可能性は2つだけ(89)であり、間違う確率は1/2しかない。取り得る値の最も少ないマスを選ぶことで正しい選択をする見込みを高くするのだ。値の順序については特別なことは何もせず、数字の小さい順に検討していく。
これで探索関数searchを使ってsolveを定義する準備ができた。
def solve(grid): return search(parse_grid(grid))
def search(values):
"深さ優先探索と制約伝播を使い、すべての可能なvaluesを試す。"
if values is False:
return False ## 前の時点で失敗している
if all(len(values[s]) == 1 for s in squares):
return values ## 解けた!
## 取り得る値の個数が最小である未確定のマスsを選ぶ
n,s = min((len(values[s]), s) for s in squares if len(values[s]) > 1)
return some(search(assign(values.copy(), s, d))
for d in values[s])
def some(seq):
"seqの要素からtrueであるものをどれか返す。"
for e in seq:
if e: return e
return False
これで完成だ! 1ページ足らずのコードで、どんな数独パズルでも解けるようになった。
完全なプログラムはここにある。以下はコマンドラインで実行した出力結果で、 50個のやさしいパズルと 95個の難しいパズルの2つのファイル( 95個のパズルの解答も参照)、 “hardest sudoku”(最も難しい数独)で検索して見つけた 11個のパズル、それにランダムに選んだ99個のパズルを解いている。
% python sudo.py All tests pass. Solved 50 of 50 easy puzzles (avg 0.01 secs (86 Hz), max 0.03 secs). Solved 95 of 95 hard puzzles (avg 0.04 secs (24 Hz), max 0.18 secs). Solved 11 of 11 hardest puzzles (avg 0.01 secs (71 Hz), max 0.02 secs). Solved 99 of 99 random puzzles (avg 0.01 secs (85 Hz), max 0.02 secs).
>>> solve_all(from_file("hardest.txt")[0:2], 'Inkala')
8 5 . |. . 2 |4 . .
7 2 . |. . . |. . 9
. . 4 |. . . |. . .
------+------+------
. . . |1 . 7 |. . 2
3 . 5 |. . . |9 . .
. 4 . |. . . |. . .
------+------+------
. . . |. 8 . |. 7 .
. 1 7 |. . . |. . .
. . . |. 3 6 |. 4 .
8 5 9 |6 1 2 |4 3 7
7 2 3 |8 5 4 |1 6 9
1 6 4 |3 7 9 |5 2 8
------+------+------
9 8 6 |1 4 7 |3 5 2
3 7 5 |2 6 8 |9 1 4
2 4 1 |5 9 3 |7 8 6
------+------+------
4 3 2 |9 8 1 |6 7 5
6 1 7 |4 2 5 |8 9 3
5 9 8 |7 3 6 |2 4 1
(0.01 seconds)
. . 5 |3 . . |. . .
8 . . |. . . |. 2 .
. 7 . |. 1 . |5 . .
------+------+------
4 . . |. . 5 |3 . .
. 1 . |. 7 . |. . 6
. . 3 |2 . . |. 8 .
------+------+------
. 6 . |5 . . |. . 9
. . 4 |. . . |. 3 .
. . . |. . 9 |7 . .
1 4 5 |3 2 7 |6 9 8
8 3 9 |6 5 4 |1 2 7
6 7 2 |9 1 8 |5 4 3
------+------+------
4 9 6 |1 8 5 |3 7 2
2 1 8 |4 7 3 |9 5 6
7 5 3 |2 9 6 |4 8 1
------+------+------
3 6 7 |5 4 2 |8 1 9
9 8 4 |7 6 1 |2 3 5
5 2 1 |8 3 9 |7 6 4
(0.01 seconds)
Solved 2 of 2 Inkala puzzles (avg 0.01 secs (99 Hz), max 0.01 secs).
本当に難しい問題がほしければ自分で作らなければならないようだ。難しい問題はどうすれば作れるのかわからないので、百万個のパズルをランダムに生成することにした。このランダムにパズルを生成するアルゴリズムは単純だ。まずマスの順序をランダムにシャッフルする。それぞれのマスに1つひとつランダムに選んだ数字を入れ、可能な数字が選択されることを期待する。矛盾が生じたらやり直す。17以上のマスを8種類以上の数字で埋めることができたらそれで終わりだ。(メモ: 埋められているマスが17個未満か、使われている数字が8種未満だと、解が複数になることが知られている。8種の数字のことを指摘してくれたOlivier Grégoireに感謝する。) これらのチェックをしても、ランダムに生成したパズルが解を1つだけ持つとは保証できない。複数の解を持つものがたくさんあり、解を持たないものもわずかながらある(約0.2%)。本や新聞に載っているパズルの場合は、解が必ず1つだけある。
ランダムなパズルを解くのにかかる平均時間は0.01秒で、99.95%以上は0.1秒未満で解けるが、ごく一部ずっと長くかかるものがある。
0.032% (3,000に1つ) は0.1秒以上かかる 0.014% (7,000に1つ) は1秒以上かかる 0.003% (30,000に1つ) は10秒以上かかる 0.0001% (1,000,000に1つ) は100秒以上かかる
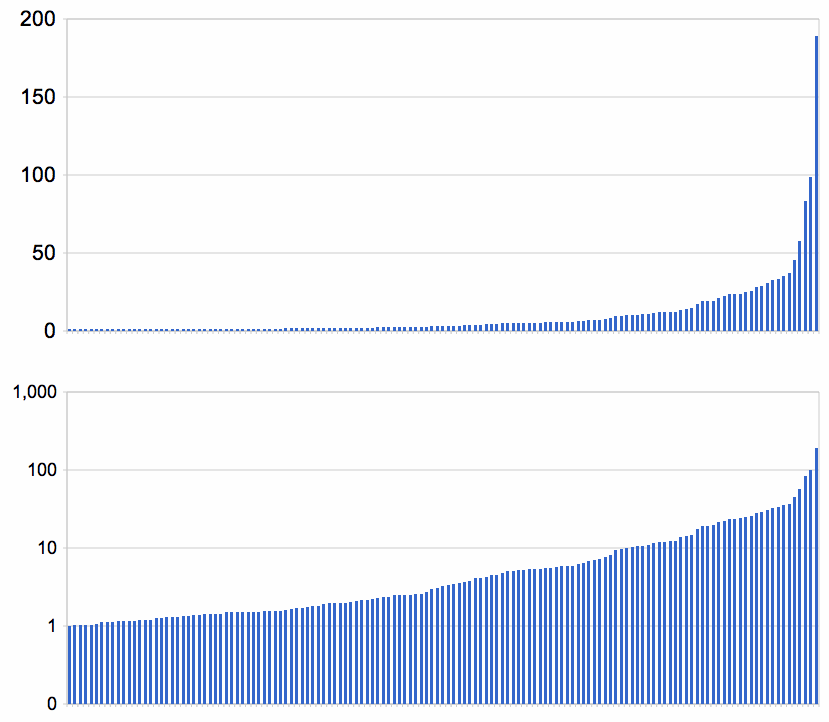
以下は1秒以上かかった100万個中の139個について、秒単位の時間をソートして線形スケールとログスケールで表したものだ。
これから結論を引き出すのは難しい。最後のいくつかの値が突出しているのは果たして重要なのだろうか? 1000万個のパズルを生成したら、1000秒かかるものが出てくるのだろうか? 以下は、100万個のパズルの中で、(私のプログラムに関して)最も難しい問題だ。
>>> hard1 = '.....6....59.....82....8....45........3........6..3.54...325..6..................' >>> solve_all([hard1]) . . . |. . 6 |. . . . 5 9 |. . . |. . 8 2 . . |. . 8 |. . . ------+------+------ . 4 5 |. . . |. . . . . 3 |. . . |. . . . . 6 |. . 3 |. 5 4 ------+------+------ . . . |3 2 5 |. . 6 . . . |. . . |. . . . . . |. . . |. . . 4 3 8 |7 9 6 |2 1 5 6 5 9 |1 3 2 |4 7 8 2 7 1 |4 5 8 |6 9 3 ------+------+------ 8 4 5 |2 1 9 |3 6 7 7 1 3 |5 6 4 |8 2 9 9 2 6 |8 7 3 |1 5 4 ------+------+------ 1 9 4 |3 2 5 |7 8 6 3 6 2 |9 8 7 |5 4 1 5 8 7 |6 4 1 |9 3 2 (188.79 seconds)
あいにくとこの問題には解が複数あって本当の数独パズルとは言えない。(これは8種類以上の文字があるかチェックすべきだというOlivier Grégoireの指摘を反映する前に生成したもので、この問題の解に対し、1と7を入れ替えたものもまた解になる。) しかしこれは本質的に難しいパズルなのだろうか? それとも私の探索ルーチンの変数の順序づけと値の順序づけのやり方のために、たまたま難しくなっているのだろうか? それを確認するため、値の順序づけに乱数を入れてみた(search関数の最後の行のfor d in values[s]の部分をfor d in shuffled(values[s])で置き換え、random.shuffleを使ってshuffledを実装した)。結果は極端な二山分布になった。30回やったうちの27回は0.02秒以内に解けたが、残りの3回は190秒ほどかかった(約1万倍余計にかかっているわけだ)。このパズルには複数の解があり、乱択を入れた探索で13の異なる解が見つかった。私の想像では、探索の早い時点である一連のマス(たぶん2つ)にまずい値を割り当てると、矛盾が見つかるまでに190秒かかることになる一方、別な割り当てをした場合には、速やかに解が見つかるか、矛盾が見つかって別な選択に移行するのだろうと思う。だからアルゴリズムの早さは値の選択で致命的な組み合わせを避けられるかどうかで決まることになる。 乱択は多くの場合にうまくいくが(30回中27回)、もっと良い値の順序づけ方法か(良く使われるヒューリスティックスは最小制約値法で、ピアに課する制約が一番少ない値を選択するというものだ)、もっとうまい変数の順序づけ方法を使うことで改良できるかもしれない。
難しいパズルがどういうものかうまく特徴づけるためには、もっと実験をする必要がある。100万のランダムなパズルの実験をもう一度することにし、今度は実行時間の50、90、99パーセンタイルと、最大値、標準偏差の統計を取ってみることにした。結果は同様だったが、今回は100秒以上かかったパズルが2つあり、そのうちの1つには1439秒という非常に長い時間がかかった。このパズルは0.2%の解を持たないパズルの1つであることがわかったので問題はない。しかしここでの大きな知見は、サンプルを増やしても平均と中央値はさほど変わらないが、最大値は劇的に大きくなるということだ。標準偏差も増えるが、これは99パーセンタイルより上の、ごくわずかの非常に長くかかるケースのためだ。これは普通でない重いしっぽを持つ分布になるのだ。
比較として、以下で左の表はパズルを解くのにかかる時間の統計、右の表は平均0.014、標準偏差1.4794の正規分布のサンプルだ。100万のサンプルで、正規分布では最大値は平均から標準偏差の5倍離れているのに対し、パズルを解く時間の最大値は平均値より標準偏差の1000倍離れている。
| パズルの実行時間のサンプル | N(0.014, 1.4794)のサンプル | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
以下は1439秒かかった解けないパズルだ。
. . . |. . 5 |. 8 . . . . |6 . 1 |. 4 3 . . . |. . . |. . . ------+------+------ . 1 . |5 . . |. . . . . . |1 . 6 |. . . 3 . . |. . . |. . 5 ------+------+------ 5 3 . |. . . |. 6 1 . . . |. . . |. . 4 . . . |. . . |. . .
以下はsolve_allのコードで、ファイルから読んだパズルとランダムに生成したパズルを確認するのに使った。
import time, random
def solve_all(grids, name='', showif=0.0):
"""一連のgridを解こうと試み、結果をレポートする。
showifが秒数の場合、それより長くかかったパズルを表示する。
showifがNoneの場合、パズルの表示は行わない。"""
def time_solve(grid):
start = time.clock()
values = solve(grid)
t = time.clock()-start
## 長くかかったパズルを表示する
if showif is not None and t > showif:
display(grid_values(grid))
if values: display(values)
print '(%.2f seconds)\n' % t
return (t, solved(values))
times, results = zip(*[time_solve(grid) for grid in grids])
N = len(grids)
if N > 1:
print "Solved %d of %d %s puzzles (avg %.2f secs (%d Hz), max %.2f secs)." % (
sum(results), N, name, sum(times)/N, N/sum(times), max(times))
def solved(values):
"それぞれのユニットが1から9の順列になっているならパズルは解けている"
def unitsolved(unit): return set(values[s] for s in unit) == set(digits)
return values is not False and all(unitsolved(unit) for unit in unitlist)
def from_file(filename, sep='\n'):
"sepを区切り文字として、ファイルを文字列のリストへと分解する。"
return file(filename).read().strip().split(sep)
def random_puzzle(N=17):
"""Nカ所以上割り当てられたランダムなパズルを作る。矛盾が起きた場合はやり直す。
結果のパズルが解けるという保証はないが、経験的には、
約99.8%は解けるものになっている。複数の解を持つものもある。"""
values = dict((s, digits) for s in squares)
for s in shuffled(squares):
if not assign(values, s, random.choice(values[s])):
break
ds = [values[s] for s in squares if len(values[s]) == 1]
if len(ds) >= N and len(set(ds)) >= 8:
return ''.join(values[s] if len(values[s])==1 else '.' for s in squares)
return random_puzzle(N) ## あきらめて新しいパズルを作る
def shuffled(seq):
"入力列をランダムにシャッフルしたコピーを返す。"
seq = list(seq)
random.shuffle(seq)
return seq
grid1 = '003020600900305001001806400008102900700000008006708200002609500800203009005010300'
grid2 = '4.....8.5.3..........7......2.....6.....8.4......1.......6.3.7.5..2.....1.4......'
hard1 = '.....6....59.....82....8....45........3........6..3.54...325..6..................'
if __name__ == '__main__':
test()
solve_all(from_file("easy50.txt", '========'), "easy", None)
solve_all(from_file("top95.txt"), "hard", None)
solve_all(from_file("hardest.txt"), "hardest", None)
solve_all([random_puzzle() for _ in range(99)], "random", 100.0)
またJongMan Kooはこの記事を韓国語に訳している。
| home rss |
オリジナル: Solving Every Sudoku Puzzle |